Read Time:
18 Mins
AI Resume Accuracy in Enterprise Hiring: What "98%" Really Means


Every AI resume screening vendor has a slide with a big number on it. Usually it's somewhere between 95% and 99%. Sometimes it's exactly 98%. The number is presented with confidence, backed by a footnote referencing an internal study, and rarely questioned by the TA leaders sitting across the table.
That's a problem — especially for enterprise hiring teams in India managing high-volume, multi-function, and increasingly multi-geography recruitment. When ai resume accuracy in enterprise hiring is treated as a single, self-explanatory figure, the consequences show up downstream: hiring managers reviewing shortlists full of mismatched candidates, strong applicants quietly rejected by an algorithm, and niche roles staying open for months despite a "working" screening tool.
This guide breaks down what accuracy actually means in the context of AI resume screening, what questions you should be asking vendors, and how to build a screening workflow that delivers real shortlist quality — not just an impressive slide.
Accuracy is a specific technical term in machine learning. It is not a synonym for "quality," "reliability," or "fit for purpose." When a vendor says their AI resume screener is 98% accurate, they mean the model correctly classified 98% of the inputs in their test dataset. That sounds reassuring. But it tells you almost nothing about how the tool will perform on your roles, with your candidate pool, in your hiring context.
Here's the question that changes everything: What was the composition of the test dataset?
If a model is tested on a dataset where 95% of CVs are clearly unqualified — wrong industry, wrong experience level, wrong geography, then a model that simply rejects everything will score 95% accuracy. No intelligence required. The number is technically correct and practically useless.
This isn't a hypothetical edge case. It's a structural feature of how accuracy is calculated in imbalanced classification problems, which is exactly what resume screening is. Most CVs submitted for any given role are not a good fit. A model that learns to say "no" aggressively will score well on accuracy metrics while missing the candidates you actually want.
The right question isn't "how accurate is your AI?" It's "what does your AI get wrong, and how often?"
To evaluate any AI screening tool properly, you need to understand three distinct metrics that vendors routinely conflate: accuracy, precision, and recall.
Accuracy is the percentage of all predictions the model gets right, both correct passes and correct rejections. As explained above, this metric inflates in imbalanced datasets and is the least useful number for TA leaders.
Precision answers the question: of all the candidates the AI passed, how many were actually good fits? High precision means a tight, relevant shortlist. Low precision means your hiring managers are reviewing a lot of noise.
Recall answers the question: of all the candidates who were actually good fits, how many did the AI correctly identify? High recall means you're not missing strong candidates. Low recall means your best applicants are being filtered out before a human ever sees them.
These three metrics exist in tension. A model tuned for high precision will be conservative, it passes fewer candidates, but the ones it passes are more likely to be relevant. A model tuned for high recall will be permissive, it passes more candidates to avoid missing anyone good, but your shortlist gets noisier. The right balance depends entirely on your hiring context: role seniority, candidate pool size, and how much hiring manager time you can afford to spend on review.
When you see a vendor claim "98% accuracy," ask them to share precision and recall figures separately. If they can't, or won't, that tells you something important about how the number was generated. For a deeper look at how to evaluate AI screening tools on these criteria, see our guide on AI Resume Screening: How to Choose the Right Tool in 2026.
An AI model's accuracy is only as good as the data it was trained on. This is not a caveat, it is the central fact of machine learning. And for enterprise hiring teams, it has direct, practical consequences.
A model trained predominantly on software engineering CVs will underperform on pharma regulatory roles, manufacturing quality assurance positions, or finance shared-services profiles. The language, credential structures, and career progression patterns are different enough that a model without domain-specific training will make systematic errors. If a vendor can't tell you which job categories their model was trained on, and in what proportions, you have no way to assess whether it will work for your specific hiring needs.
More training data generally means better generalisation, but volume alone isn't sufficient. A model trained on 250,000 anonymised resumes across 570+ job categories has meaningfully broader coverage than one trained on 50,000 CVs from a single industry. The breadth of job categories matters as much as the raw number, especially for enterprise teams hiring across functions and geographies simultaneously.
Job titles, required skills, and role structures change faster than most AI models are retrained. A model trained on data from 2021 or 2022 may not recognise "AI Prompt Engineer," "ESG Compliance Lead," or "GCC Delivery Head" as meaningful role categories. For Indian mid-market companies hiring globally in 2026, this recency gap can translate directly into missed candidates for emerging or hybrid roles.
This is the issue most relevant to Indian enterprises hiring outside India. If a model was trained primarily on CVs from North American or Western European candidates, it will have learned formatting conventions, credential structures, and career narrative patterns that don't apply to candidates from Southeast Asia, Eastern Europe, MENA, or LATAM. A candidate from Vietnam or Romania whose CV is structured differently from a US-format resume may be systematically underscored, not because they're less qualified, but because the model hasn't seen enough examples of their CV style.
For companies running global hiring from India across multiple geographies simultaneously, this geographic bias in training data is one of the most underappreciated sources of screening error.
Once you understand precision and recall, the practical implications become concrete. Every AI screening error falls into one of two categories, and each has a different cost.

A false positive is a candidate the AI passes who shouldn't have been shortlisted. They reach your hiring manager's desk, consume review time, and may even get to interview before the mismatch becomes obvious. The cost is wasted time and reduced hiring manager confidence in the screening process.
A false negative is a candidate the AI rejects who should have been shortlisted. They never reach a human reviewer. You don't know they existed. The cost is invisible, a great hire you never made, a role that stays open longer, a team that underperforms because the right person was filtered out by an algorithm.
In enterprise hiring, false negatives are typically more damaging than false positives. A false positive costs a hiring manager 20 minutes. A false negative for a senior niche role can cost months of additional search time, plus the downstream business impact of the role remaining vacant. Research on the hidden cost of roles left open consistently shows that the financial impact of a vacant senior position compounds quickly.
The compounding effect is particularly acute for Indian enterprises running multi-geo hiring. If your AI screening tool has a 5% false negative rate and you're processing 200 CVs across three geographies for a single role, you're statistically eliminating 10 potentially qualified candidates before a human ever reviews them. Across a portfolio of 20 open roles, that's 200 missed candidates, some of whom may have been your best hires.
For specialist or senior roles, the candidate pool is already small. A false negative rate that's acceptable for a high-volume graduate intake becomes catastrophic when you're screening 40 CVs for a regulatory affairs director in Germany or a semiconductor process engineer in South Korea. The smaller the qualified pool, the more each individual screening error matters.
The most effective response to the limitations of AI accuracy isn't to find a better algorithm. It's to build a screening architecture where AI and human judgment operate at the layers where each performs best.
A single-layer AI screening model, where a CV goes in and a pass/fail decision comes out, concentrates all the risk in one place. If the model has a blind spot for a particular role type, geography, or CV format, there's no safety net. Every error propagates directly to your shortlist.
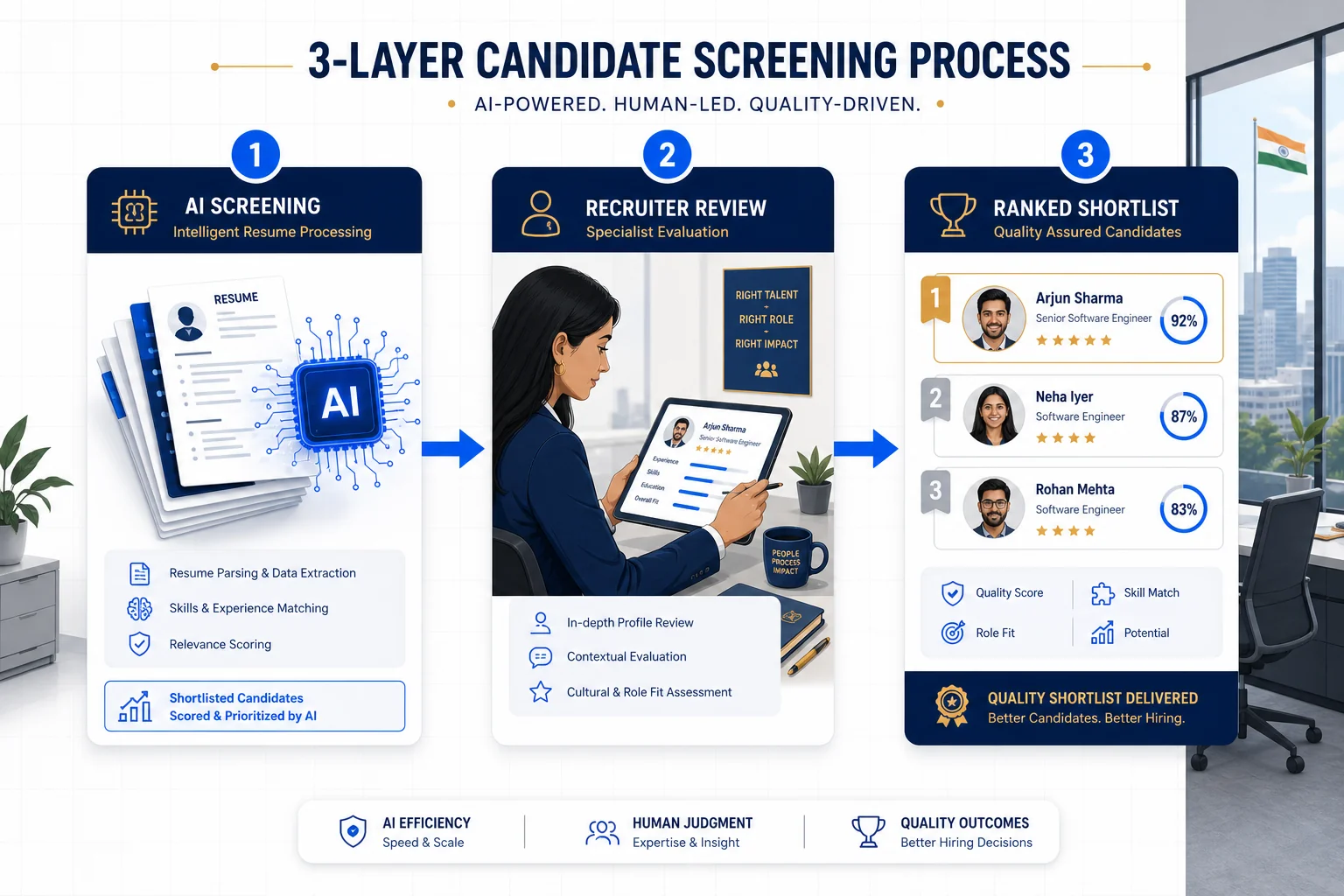
A multi-layer model distributes that risk. Consider a three-level approach:
This is the architecture behind CBREX's C Screen tool, which combines specialist agency pre-screening with AI validation across 570+ job categories. The result is that the AI operates on inputs that have already been filtered by human domain expertise, which means its errors have less downstream impact, and its strengths (speed, consistency, scale) are fully leveraged.
The three-level model also addresses the geographic bias problem. A specialist recruiter in Southeast Asia or Eastern Europe brings local market knowledge that a globally-trained AI model may lack. Their pre-screen catches the candidates a geographically biased model might have missed. For more on how this layered approach works in practice, see our detailed breakdown of candidate screening in 2026.
Armed with the above, here are the specific questions that separate a genuinely capable AI screening tool from one that's good at producing impressive slides.
Abstract accuracy metrics become meaningful when you translate them into workflow outcomes. For enterprise hiring teams in India, particularly those managing multi-function, multi-geography recruitment, the practical benchmarks that matter are:
What percentage of candidates on your AI-generated shortlist actually get invited to interview? A well-calibrated screening tool should produce shortlists where 60-80% of candidates are interview-worthy. If your hiring managers are routinely rejecting more than half the shortlist, your false positive rate is too high. If they're consistently saying "there should be more candidates in this pool," your false negative rate is the problem.
This metric captures the quality of candidates who make it through screening. A high interview-to-offer rate suggests the screening layer is doing its job, surfacing candidates who are genuinely strong fits, not just technically qualified. For niche roles, a 1-in-3 interview-to-offer rate is a reasonable benchmark. For senior leadership roles, 1-in-5 is more typical given the complexity of fit assessment at that level.
Speed matters, but not at the expense of quality. The right benchmark is the time from role briefing to a shortlist your hiring manager is willing to act on, not the time to any shortlist. An AI tool that produces a shortlist in 24 hours but requires three rounds of revision before it's usable is not faster than a tool that takes 72 hours and delivers a shortlist that goes straight to interview scheduling.
For Indian mid-market companies hiring across multiple countries, screening accuracy should be evaluated separately for each geography. A tool that performs well for roles in India may underperform for positions in Germany, Singapore, or Brazil. Track shortlist quality metrics by geography and push your vendor for performance data broken out the same way.
This geographic dimension is where the combination of AI screening and specialist local agency networks becomes particularly powerful. Agencies with on-the-ground expertise in specific markets bring local context that improves the quality of inputs to the AI layer, which in turn improves the accuracy of the output. For companies managing niche skills hiring overseas, this combination is often the difference between a role filled in six weeks and one that stays open for six months.
The practical takeaway from everything above is straightforward: don't outsource your quality bar to a single accuracy metric. Build a screening workflow with multiple checkpoints, clear feedback loops, and metrics that reflect real hiring outcomes rather than model performance on a test dataset.
Before evaluating any AI screening tool, define what success looks like for your specific hiring context. Shortlist-to-interview rate. Interview-to-offer rate. Time-to-shortlist by role category. These are the numbers that matter to your business. Any vendor who can't show you their tool's performance on these metrics, not just their internal accuracy figure, is asking you to buy on faith.
AI screening tools improve with feedback. If your hiring managers are consistently rejecting certain types of candidates that the AI is passing, that signal needs to flow back into the model. Most enterprise AI screening tools support some form of feedback mechanism, but many TA teams don't use them systematically. A structured feedback loop between hiring managers and the screening layer is one of the highest-leverage improvements most enterprise teams can make to their screening accuracy.
AI screening excels at speed, consistency, and scale. It can process 500 CVs in the time a human reviewer would take to read 10. It applies the same criteria to every candidate without fatigue or unconscious variation. These are genuine advantages, but they're advantages in the context of a well-designed workflow, not a replacement for human judgment at the stages where human judgment matters most.
For niche and senior roles, the human layer is not optional. A specialist recruiter's ability to read a career trajectory, assess domain credibility, and identify candidates who are a strong cultural fit for a specific organisation is not something a current AI model can replicate. The right architecture uses AI to handle volume and consistency, and human expertise to handle nuance and judgment. This is exactly the model that makes RPO and agency models more effective when combined with AI rather than replaced by it.
If you're already using an AI screening tool, run a retrospective audit. Take the last 50 roles where the tool was used. For each role, calculate: how many candidates did the AI pass? How many were invited to interview? How many received offers? Compare these numbers to roles where human-only screening was used. The gap between your tool's claimed accuracy and its real-world performance on your roles is the number that should drive your next vendor conversation.
For a broader view of how to evaluate your entire recruitment technology stack, our guide on hiring platforms in India covers the full landscape of options and how to assess them against your specific needs.
It depends entirely on what that 98% measures. If it's overall accuracy on an imbalanced test dataset, it may be nearly meaningless for your use case. Ask for precision and recall figures broken out by role category, and evaluate the tool's performance on your actual shortlist quality metrics rather than the vendor's internal benchmark.
Run a parallel test on a set of recently filled roles. Feed the historical CVs through the AI tool and compare its shortlist to the candidates who were actually hired. Calculate the false negative rate, how many of your eventual hires would the AI have rejected? This retrospective test is the most reliable way to assess real-world performance before you commit.
Some can, most can't, at least not reliably. Ask vendors specifically about their performance on CVs in languages other than English, and on CVs from the specific geographies where you're hiring. For Indian enterprises hiring across APAC, MENA, and Eastern Europe, this is a non-negotiable capability to verify before deployment.
Accuracy is a model performance metric measured on a test dataset. Shortlist quality is a business outcome metric measured on your actual hiring pipeline. A tool can have high accuracy and poor shortlist quality if the test dataset doesn't reflect your candidate pool. Always evaluate tools on shortlist quality metrics, shortlist-to-interview rate, interview-to-offer rate, not just the vendor's accuracy claim.
C Screen is trained on 250,000+ anonymised resumes across 570+ job categories, giving it broad domain coverage. More importantly, it operates as the second layer in a three-level screening process, after specialist agency pre-screening and before stack ranking. This means the AI is validating candidates who have already been reviewed by a human domain expert, which significantly reduces the impact of model errors and improves the quality of the final shortlist.
The next time a vendor presents their ai resume accuracy in enterprise hiring figure, you now have the framework to ask the right questions. What does that number measure? What's the false negative rate? How does the model perform on your specific role categories and geographies? What human validation layer exists to catch model errors?
These aren't hostile questions. They're the questions any serious TA leader should be asking before trusting an algorithm with their hiring pipeline. The difference between a screening tool that delivers genuine shortlist quality and one that just produces an impressive slide is visible in the answers.
CBREX's C Screen combines AI validation trained on 250,000+ resumes across 570+ job categories with specialist agency pre-screening and stack ranking, so the accuracy figure reflects real shortlist quality, not just model performance on a test set. If you're managing enterprise hiring across multiple functions and geographies and want to see what a genuinely layered screening approach looks like in practice, book a demo with the CBREX team and bring your hardest roles. We'll show you exactly how the screening works, and what the numbers actually mean.
Not ready for a demo yet? Sign up on CBREX to explore the platform, or reach out directly if you'd prefer to talk through your specific screening challenges first.







